強化学習の勉強 方策勾配法でMountainCarを試す
OpenAI Gym 入門 - Qiita
この方の記事を参考に方策勾配法でMountainCarを試しました。
強化学習の勉強をする上で環境(ゲーム)を作るが大変だったのですが、OpenAIのgymは一瞬で環境を構築できるので感動しました。
使うのはこれだけ
import gym import numpy as np
環境はこれで定義します。
他にも色々な環境が用意されていたので、後日試したいと思います。
env = gym.make('MountainCar-v0')
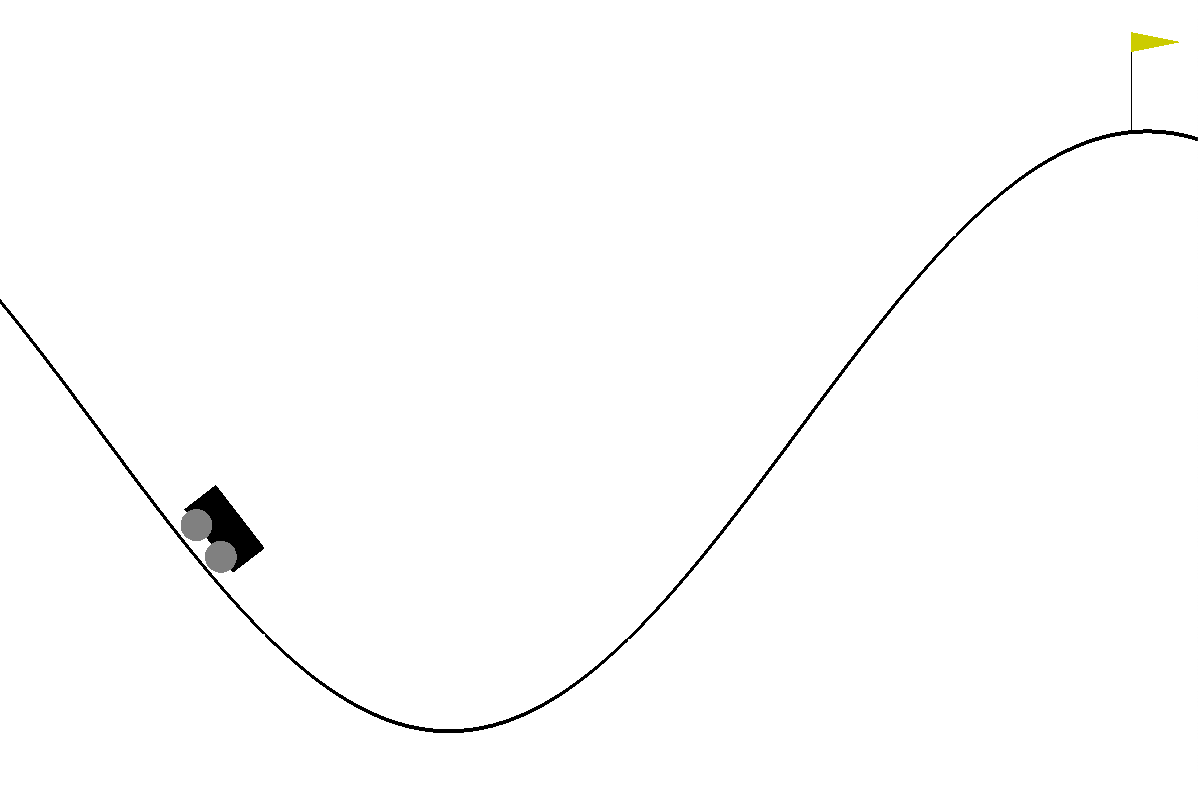
この環境は2つの山に囲まれた谷から車を脱出させるというゲームですが、車のエンジンが弱い為、重力を利用しながら加速してゴールを目指さなくてはなりません。
状態は
・位置: -1.2〜0.6 (位置が0.5よりも大きくなったらゴール)
・速度: -0.07〜0.07
行動は
・[0]で左にアクセル
・[1]でなにもしない
・[2]で右にアクセル
env.step(action)
で状態、報酬、ゲーム終了フラグ、詳細情報を取り出せます。
MountainCarの場合は報酬は常に-1で、200ステップ経つと強制終了です。
200ステップ以内にゴールすることを目指します。
環境の初期化は
env = gym.make('MountainCar-v0')
で行います。
得られる状態は連続値であるため、40個の離散値に変換します。上で紹介した記事と同じです。
def get_status(observation): env_low = env.observation_space.low # 位置と速度の最小値 env_high = env.observation_space.high # 位置と速度の最大値 env_dx = (env_high - env_low) / 40 # 40等分 # 0〜39の離散値に変換する position = int((observation[0] - env_low[0])/env_dx[0]) velocity = int((observation[1] - env_low[1])/env_dx[1]) return position, velocity
まずは方策のパラメータを初期化します。
位置40個、速度40個、行動3個なので、方策のパラメータはの形状です。
theta = np.random.rand(40, 40, 3)
から方策
を得ます。
Softmax関数を用いて、各状態における各行動の確率を計算しています。
Softmaxはの値によってはオーバーフローを起こす可能性があるので、
の最大値を使って値を小さくします。
また、phi=1は今はよく理解していませんが、基底関数を定義することで何かいいことがあるみたい??
def get_pi(theta): phi = 1 [l, m, n] = theta.shape pi = np.zeros((l, m, n)) for i in range(l): for j in range(m): for k in range(n): c = np.max(theta[i,j]) #オーバーフローを回避する為の定数 pi[i,j,k] = np.exp(phi*(theta[i,j,k]-c)) / np.sum(np.exp(phi*(theta[i,j]-c))) return pi
現在の状態から行動を得ます。方策勾配法は、確率的方策なので確率に従って行動を選びます。
np.random.choiceでは確率の合計が1でなくてはならないのですが、数値誤差で1にならない可能性も考え、np.sumを使って強制的に合計値を1にしています。
def get_action(pi, observation): position, velocity = get_status(observation) action = np.random.choice([0,1,2], p=pi[position, velocity]/np.sum(pi[position, velocity])) return action
報酬関数を定義します。
MountainCarでは報酬が常に-1ですが、この報酬だとうまくいかなかったので、報酬関数を作りました。
現在の状態と1時刻前の状態の位置と速度の絶対値が報酬です。
また、ただ早く大きく動くだけでなく、ゴールを目指して欲しいので、ゴールに達したら特別に報酬を与えています。
報酬関数の設計の仕方で車の動きがかなり変わりました。
報酬関数の設計を強化学習させる逆強化学習なるものがあるそうなので、いずれ試したいと思います。
def reward_func(observation, _observation): position, velocity = get_status(observation) _position, _velocity = get_status(_observation) if position >= 37: #位置0.5以上でエピソードが終了である為、ゴールしたら特別に報酬を与える(位置0.5は37番目の状態) reward = np.abs(velocity - _velocity) + np.abs(position - _position) + 100 else: reward = np.abs(velocity - _velocity) + np.abs(position - _position) return reward
方策勾配法では、M回Tステップのエピソードを使って、方策のパラメータを更新します。
この方法をモンテカルロ近似というらしいです。
の更新式は
です。
は学習率、
は確率的方策の良さを量る量の勾配です。
は割引報酬和の期待値で定義されるみたいです。
興味があるのは勾配なので、を計算します。
と
はmエピソード目のtステップ目の状態とそのときの行動です。
行動価値はなんらかの手法で近似しますが、今回は即時報酬で近似するREINFORCE アルゴリズムを使います。
ちなみに、行動価値はQ-learningで使うやつですが、環境がでかいとメモリを食いまくる為、そういう問題を扱うときは方策勾配法が選ばれるようです。
ロボットに強化学習させることを考えると、環境は位置X,Y,Z,W,R,Pだったり各軸値だったり、速度だったり、たしかにメモリを食いそうな環境だと思いました。
とにかく、なにも学習させずにM回のエピソードを回します。
R_listは各ステップの状態、行動、報酬を記録するリストです。
goal_countは後で学習結果を確認する為の記録用変数です。
def run_Mepisode(M, pi): R_list = [] goal_count = 0 for i in range(M): total_reward = 0 observation = env.reset() R_log = [] for j in range(200): # 現在の状態を取得 position, velocity = get_status(observation) _observation = observation.copy() #env.render() # 行動を選択 action = get_action(pi, _observation) # 車を動かし、観測結果・報酬・ゲーム終了FLG・詳細情報を取得 observation, reward, done, _ = env.step(action) position, velocity = get_status(observation) reward = reward_func(observation, _observation) # nabla_J計算用に各ステップにおける状態、行動、報酬を記録 R = np.array([position, velocity, action, reward]) R_log.append(R) # 報酬の合計値を計算 total_reward += reward if done: R_list.append(R_log) if j < 199: goal_count += 1 # doneがTrueになったら1エピソード終了 break env.close() return R_list, total_reward, goal_count
M回のエピソードから色々データを取ってきたので、を計算します。
REINFORCE では、
と計算します。
bは平均報酬で、
です。
R_listというリストが少々複雑なのですが、M回のエピソードについて各ステップでの状態(位置、速度)、行動、報酬が記録されています。
例えば、R_list[5]は6回目のエピソードにおける各ステップでの推移です。
R_list[5][3]とすれば、6回目のエピソードの4回目のステップでの状態、行動、報酬を見ることができます。
nabla_J[R_list[i][j][0], R_list[i][j][1], R_list[i][j][2]]は
R_list[i][j][0]が位置、
R_list[i][j][1]が速度、
R_list[i][j][2]が行動
である為、その状態におけるその行動の良さの勾配が要素となっています。
def get_nabla_J(pi, R_list): b = np.zeros((40,40,3)) for i in range(len(R_list)): _b = np.zeros((40,40,3)) for j in range(len(R_list[i])): _b[R_list[i][j][0], R_list[i][j][1], R_list[i][j][2]] += R_list[i][j][3] b += -b/len(R_list[i]) b /= len(R_list) nabla_J = np.zeros((40,40,3)) nabla_log_pi = 1-pi for i in range(len(R_list)): for j in range(len(R_list[i])): nabla_J[R_list[i][j][0], R_list[i][j][1], R_list[i][j][2]] += (R_list[i][j][3]- b[R_list[i][j][0], R_list[i][j][1], R_list[i][j][2]]) * nabla_log_pi[R_list[i][j][0], R_list[i][j][1], R_list[i][j][2]] return nabla_J
こうのような、プログラムにしたのですが悩んでいることがあります。
Softmaxの微分についてです。
で微分
のとき
のとき
のとき、
で微分すると
となる。
従って、各で微分すると、
となる。
の更新は
であるから、形を合わせる為にのときの
だけを使うことにした。
つまり、
これが合ってるのか誰か教えて欲しい。。
うまく動いているぽかったので、たぶん合っているのだと信じます。
あとは、を更新するだけです。
def update_theta(theta, nabla_J): eta = 0.1 theta_ = theta.copy() theta = theta_ + eta * nabla_J return theta
gymではenv.render()というものを使うことで、ゲームの画面が表示されます。
結構楽しいので、学習後の車の動きを見られる関数も作っておきます。
def view_result(theta): pi = get_pi(theta) observation = env.reset() total_reward = 0 step_count = 0 while True: env.render() _observation = observation.copy() action = get_action(pi, _observation) observation, reward, done, _ = env.step(action) reward = reward_func(observation, _observation) total_reward += reward step_count += 1 print("step: {} total_reward: {}".format(step_count, total_reward)) if done: break env.close()
これで完成です。
if __name__ == '__main__': env = gym.make('MountainCar-v0') #方策のパラメータthetaを初期化 theta = np.random.rand(40, 40, 3) result = [] # M回のエピソードをN回繰り返す M = 20 N = 500 for i in range(N): observation = env.reset() pi = get_pi(theta) R_list, total_reward, goal_count = run_Mepisode(M, pi) nabla_J = get_nabla_J(pi, R_list) theta = update_theta(theta, nabla_J) result.append(goal_count) print("episode: {}/{} total_reward: {}".format(i*M, M*N, total_reward)) # 5回動きを見る for i in range(5): view_result(theta) print(get_pi(theta)) # 結果の可視化 import matplotlib.pyplot as plt fig, ax = plt.subplots(figsize=(7,4), dpi=100) ax.plot(result) ax.grid() plt.plot()
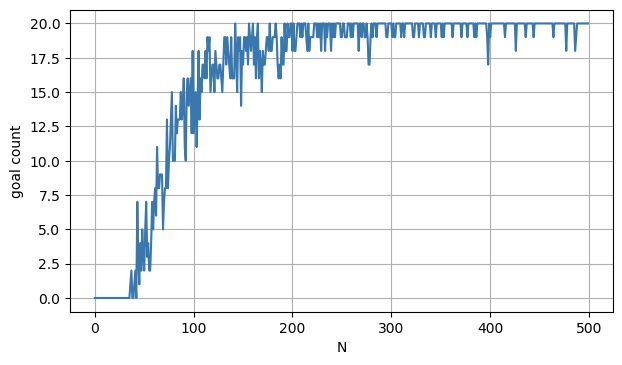
20回のエピソードを500回繰り返して学習した結果です。
おおよそ、4000(20エピソード×200回)あたりから、ほぼゴールにたどり着くようになりました。
ちなみに、報酬関数を使わず、-1で報酬を固定した場合は学習せず、行動1の何もしないを取り続けるだけでした。
報酬関数の次第で大きく結果が変わるということが分かりました。